Macro Gallery
Images Shot by Nex 5N plus these lens:
- Panagor PMC 90mm 2.8 Macro 1:1
- Soligor C/D 35-70mm 2.5-3.5
- Helios 44M-2
- Helios 44M-4
- Helios 44m-6

Images Shot by Nex 5N plus these lens:
http://thegeekdiary.com/solaris-zfs-command-line-reference-cheat-sheet/
| # zpool create datapool c0t0d0 | Create a basic pool named datapool |
| # zpool create -f datapool c0t0d0 | Force the creation of a pool |
| # zpool create -m /data datapool c0t0d0 | Create a pool with a different mount point than the default. |
| # zpool create datapool raidz c3t0d0 c3t1d0 c3t2d0 | Create RAID-Z vdev pool |
| # zpool add datapool raidz c4t0d0 c4t1d0 c4t2d0 | Add RAID-Z vdev to pool datapool |
| # zpool create datapool raidz1 c0t0d0 c0t1d0 c0t2d0 c0t3d0 c0t4d0 c0t5d0 | Create RAID-Z1 pool |
| # zpool create datapool raidz2 c0t0d0 c0t1d0 c0t2d0 c0t3d0 c0t4d0 c0t5d0 | Create RAID-Z2 pool |
| # zpool create datapool mirror c0t0d0 c0t5d0 | Mirror c0t0d0 to c0t5d0 |
| # zpool create datapool mirror c0t0d0 c0t5d0 mirror c0t2d0 c0t4d0 | disk c0t0d0 is mirrored with c0t5d0 and disk c0t2d0 is mirrored withc0t4d0 |
| # zpool add datapool mirror c3t0d0 c3t1d0 | Add new mirrored vdev to datapool |
| # zpool add datapool spare c1t3d0 | Add spare device c1t3d0 to the datapool |
| ## zpool create -n geekpool c1t3d0 | Do a dry run on pool creation |
| # zpool status -x | Show pool status |
| # zpool status -v datapool | Show individual pool status in verbose mode |
| # zpool list | Show all the pools |
| # zpool list -o name,size | Show particular properties of all the pools (here, name and size) |
| # zpool list -Ho name | Show all pools without headers and columns |
| # zfs create datapool/fs1 | Create file-system fs1 under datapool |
| # zfs create -V 1gb datapool/vol01 | Create 1 GB volume (Block device) in datapool |
| # zfs destroy -r datapool | destroy datapool and all datasets under it. |
| # zfs destroy -fr datapool/data | destroy file-system or volume (data) and all related snapshots |
| # zfs set quota=1G datapool/fs1 | Set quota of 1 GB on filesystem fs1 |
| # zfs set reservation=1G datapool/fs1 | Set Reservation of 1 GB on filesystem fs1 |
| # zfs set mountpoint=legacy datapool/fs1 | Disable ZFS auto mounting and enable mounting through /etc/vfstab. |
| # zfs set sharenfs=on datapool/fs1 | Share fs1 as NFS |
| # zfs set compression=on datapool/fs1 | Enable compression on fs1 |
| # zfs create datapool/fs1 | Create file-system fs1 under datapool |
| # zfs create -V 1gb datapool/vol01 | Create 1 GB volume (Block device) in datapool |
| # zfs destroy -r datapool | destroy datapool and all datasets under it. |
| # zfs destroy -fr datapool/data | destroy file-system or volume (data) and all related snapshots |
| # zfs list | List all ZFS file system |
| # zfs get all datapool” | List all properties of a ZFS file system |
| # zfs set mountpoint=/data datapool/fs1 | Set the mount-point of file system fs1 to /data |
| # zfs mount datapool/fs1 | Mount fs1 file system |
| # zfs umount datapool/fs1 | Umount ZFS file system fs1 |
| # zfs mount -a | Mount all ZFS file systems |
| # zfs umount -a | Umount all ZFS file systems |
| # zpool iostat 2 | Display ZFS I/O Statistics every 2 seconds |
| # zpool iostat -v 2 | Display detailed ZFS I/O statistics every 2 seconds |
| # zpool scrub datapool | Run scrub on all file systems under data pool |
| # zpool offline -t datapool c0t0d0 | Temporarily offline a disk (until next reboot) |
| # zpool online | Online a disk to clear error count |
| # zpool clear | Clear error count without a need to the disk |
| # zpool import | List pools available for import |
| # zpool import -a | Imports all pools found in the search directories |
| # zpool import -d | To search for pools with block devices not located in /dev/dsk |
| # zpool import -d /zfs datapool | Search for a pool with block devices created in /zfs |
| # zpool import oldpool newpool | Import a pool originally named oldpool under new name newpool |
| # zpool import 3987837483 | Import pool using pool ID |
| # zpool export datapool | Deport a ZFS pool named mypool |
| # zpool export -f datapool | Force the unmount and deport of a ZFS pool |
| # zfs snapshot datapool/fs1@12jan2014 | Create a snapshot named 12jan2014 of the fs1 filesystem |
| # zfs list -t snapshot | List snapshots |
| # zfs rollback -r datapool/fs1@10jan2014 | Roll back to 10jan2014 (recursively destroy intermediate snapshots) |
| # zfs rollback -rf datapool/fs1@10jan2014 | Roll back must and force unmount and remount |
| # zfs destroy datapool/fs1@10jan2014 | Destroy snapshot created earlier |
| # zfs send datapool/fs1@oct2013 > /geekpool/fs1/oct2013.bak | Take a backup of ZFS snapshot locally |
| # zfs receive anotherpool/fs1 < /geekpool/fs1/oct2013.bak | Restore from the snapshot backup backup taken |
| # zfs send datapool/fs1@oct2013 | zfs receive anotherpool/fs1 | |
| # zfs send datapool/fs1@oct2013 | ssh node02 “zfs receive testpool/testfs” | Send the snapshot to a remote system node02 |
| # zfs clone datapool/fs1@10jan2014 /clones/fs1 | Clone an existing snapshot |
| # zfs destroy datapool/fs1@10jan2014 | Destroy clone |
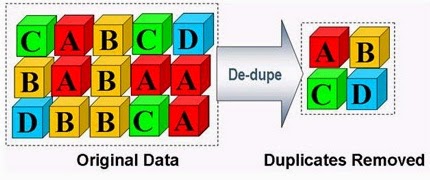
Deduplication is the process of eliminating duplicate copies of data. Dedup is generally either file-level, block-level, or byte-level. Chunks of data — files, blocks, or byte ranges — are checksummed using some hash function that uniquely identifies data with very high probability. When using a secure hash like SHA256, the probability of a hash collision is about 2^-256 = 10^-77 or, in more familiar notation, 0.00000000000000000000000000000000000000000000000000000000000000000000000000001. For reference, this is 50 orders of magnitude less likely than an undetected, uncorrected ECC memory error on the most reliable hardware you can buy.

sudo apt-get -y install python-software-properties
sudo add-apt-repository ppa:zfs-native/stable
sudo apt-get update
sudo apt-cache search zfs
sudo apt-get install ubuntu-zfs
Run the zfs commands to make sure it works
sudo zfs
sudo zpool
There is no extra configuration for ZFS running on Ubuntu
zpool command configure zfs storage pools
zfs command configure zfs filesystem
zpool list shows the total bytes of storage available in the pool.
zfs list shows the total bytes of storage available to the filesystem, after
redundancy is taken into account.
du shows the total bytes of storage used by a directory, after compression
and dedupe is taken into account.
“ls -l” shows the total bytes of storage currently used to store a file,
after compression, dedupe, thin-provisioning, sparseness, etc.
Link for reference:
https://blogs.oracle.com/bonwick/entry/zfs_dedup
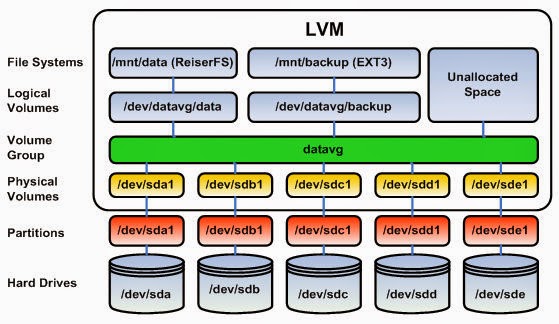
The Linux Logical Volume Manager (LVM) is a mechanism for virtualizing disks. It can create “virtual” disk partitions out of one or more physical hard drives, allowing you to grow, shrink, or move those partitions from drive to drive as your needs change.
The coolest part of Logical Volume Management is the ability to resize disks without powering off the machine or even interrupting service. Disks can be added and the volume groups can be extended onto the disks. This can be used in conjunction with software or hardware RAID as well.

Physical volumes your physical disks or disk partitions, such as /dev/hda or /dev/hdb1 -> combine multiple physical volumes into volume groups.
Volume groups comprised of real physical volumes -> create logical volumes which you can create/resize/remove and use. You can consider a volume group as a “virtual partition” which is comprised of an arbitary number of physical volumes. Ex: (VG1 = /dev/sda1 + /dev/sdb3 + /dev/sdc1)
logical volumes are the volumes that you’ll ultimately end up mounting upon your system. They can be added, removed, and resized on the fly. Since these are contained in the volume groups they can be bigger than any single physical volume you might have. (ie. 4x5Gb drives can be combined into one 20Gb volume group, and you can then create two 10Gb logical volumes.)
PVLM: Physical volumes -> Volume group -> Logical volume -> Mount on filesystem
pvcreate /dev/sda1
pvcreate /dev/sdb
pvcreate /dev/sdc2
pvdisplay
pvs
vgreate datavg /dev/sda1 /dev/sdb
vgextend datavg /dev/sdc2
vgdisplay
vgs
lvcreate -n backup –size 500G datavg
lvdisplay
lvs
mkfs.ext4 /dev/datavg/backup
mkdir /srv/backup
mount /dev/datavg/backup /srv/backup
/dev/datavg/backup /srv/backup ext4 defaults 0 2
#extend 200GB available on free space of /dev/datavg/backup
lvextend -L +200G /dev/datavg/backup
#extend the size by the amount of free space on physical volume /dev/sdc2
lvextend /dev/datavg/backup /dev/sdc2
resize2fs -p /dev/datavg/backup

